-
ABPI Website

-
Improving the UK's health data capability & the industry's access to data
- Health data and new medicines
Health data and new medicines
The discovery and development of new medicines has been a great triumph of science, helping people extend and improve their daily lives, with about 40 new medicines approved for use each year.
However, it is a long and expensive global undertaking, with more than $1.5 trillion invested by the biopharmaceutical industry in R&D across the world over the last decade – an annual spend of $179 billion in 2018.[6]
Figure 1
Health data is used by the biopharmaceutical industry at all stages of the discovery and development process, as set out in the following chart and described in more detail (see Figure 1).
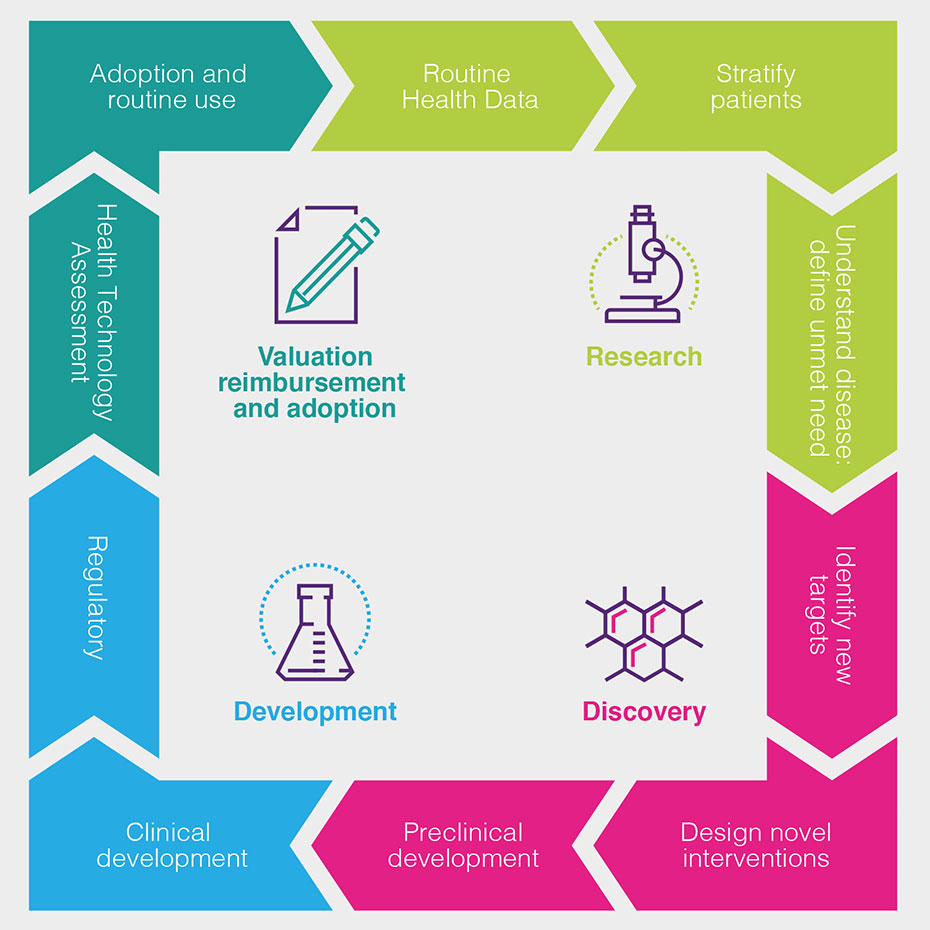
How can health data be used to drive improved patient outcomes?
The routine collection of health data about patients helps doctors, the NHS and the biopharmaceutical industry understand the effectiveness of current treatments in routine use and the progression of disease under current treatment pathways, as well as supporting pharmacovigilance – the monitoring of the safety of new medicines after their initial introduction.
It helps us learn more about the underlying cause of diseases, how to detect them earlier and how they progress – and the impact this has on patients, and the costs for healthcare systems.
Health data can help patient stratification into more meaningful groups, leading to better understanding of why some patients respond better than others, and to the refinement of disease management guidelines, treatment algorithms and patient pathways.
This patient stratification, together with historic outcomes data, can help the biopharmaceutical industry identify and define the areas of highest unmet need. This shows the industry where it should focus its research investments, and how to define and measure the success of new medicines.
Data from laboratory tests and from genomic and proteomic analysis combined with clinical data, can lead to greater understanding of disease processes. It can also help researchers to discover new targets and design new interventions to affect these targets and interfere with the disease processes.
Understanding the biochemistry of disease helps researchers to find biomarkers to indicate those patients most likely to benefit from treatments. Pre-clinical investigation will indicate whether a new treatment can be reliably administered to patients, and whether it will likely be tolerated and effective.
Once new experimental treatments have shown pre-clinical promise to enable the treatment of symptoms, the inhibition of the disease process or to offer the possibility of cure, health data can support the process of further clinical development.
Well-curated data can speed up the process of identifying and recruiting patients into clinical trials and can also help define new measures of success and trial endpoints.
For very rare patient groups or areas where it is unethical not to offer patients a new treatment, historic health data can allow researchers to find information on outcomes for untreated patients for comparison.
Data from these trials – increasingly a combination of routinely collected data and specific clinical and laboratory measures defined in the trial protocol – contributes to the regulatory submission that demonstrates that the balance between efficacy and safety warrants a marketing authorisation, allowing the medicine to be sold for use.
Further, more specific data on outcomes, costs and savings can then be used to support health technology assessments to demonstrate that a treatment represents value for money.
Health data is then used to monitor uptake of a new treatment and thus support its adoption in the health service and eventually (completing the cycle) its routine use – when the health data collected will help monitor ongoing safety, as well as evaluations of efficacy in further different patient groups.
Health data is therefore important at all points in the cycle of drug development, and the move to health data digitisation and sharing has created the potential for analysis of larger health datasets that will allow us to identify safe and effective drugs earlier in the development process, and therefore reduce the waste associated with work on drugs that subsequently are not approved.ii [7]
Furthermore, recent developments in routine genomic profiling have attracted significant industry investment, [8] with the hope that the resulting data will support the identification of new drug targets and the efficient delivery of stratified and personalised medicines (see Box 4).
Well-curated data can speed up the process of identifying and recruiting patients into clinical trials and can also help define new measures of success and trial endpoints.
For very rare patient groups or areas where it is unethical not to offer patients a new treatment, historic health data can allow researchers to find information on outcomes for untreated patients for comparison.
Data from these trials – increasingly a combination of routinely collected data and specific clinical and laboratory measures defined in the trial protocol – contributes to the regulatory submission that demonstrates that the balance between efficacy and safety warrants a marketing authorisation, allowing the medicine to be sold for use.
Further, more specific data on outcomes, costs and savings can then be used to support health technology assessments to demonstrate that a treatment represents value for money.
Health data is then used to monitor uptake of a new treatment and thus support its adoption in the health service and eventually (completing the cycle) its routine use – when the health data collected will help monitor ongoing safety, as well as evaluations of efficacy in further different patient groups.
Health data is therefore important at all points in the cycle of drug development, and the move to health data digitisation and sharing has created the potential for analysis of larger health datasets that will allow us to identify safe and effective drugs earlier in the development process, and therefore reduce the waste associated with work on drugs that subsequently are not approved.ii [7]
Furthermore, recent developments in routine genomic profiling have attracted significant industry investment, [8] with the hope that the resulting data will support the identification of new drug targets and the efficient delivery of stratified and personalised medicines (see Box 4).
Box 4: Investments by the global biopharmaceutical industry in health data resources
In 2018, GSK invested in US company 23andMe and its database of genetic and phenotypic data.[9]
In 2015, Roche acquired a majority stake in molecular and genomic analysis business Foundation Medicine,[10] and took full ownership in June 2018.[11]
In 2012, Amgen acquired DeCODE Genetics which held genetic and clinical data on the Icelandic population. In June 2019, DeCODE announced a major collaboration with US-based healthcare delivery network Intermountain Healthcare, which aims to analyse the genomes of 500,000 people from Intermountain’s patient population in Utah and Idaho.[12]
What is the opportunity for the UK?
Given that well curated health data can support each step in the process of developing new medicines, and given the scale of health data generation and collection in the NHS, the UK should be well placed to attract a larger share of the annual $179 billion [6] global industry investment in clinical development and early research – contributing to the Government’s overall ambition for R&D spending to reach 2.4% of GDP by 2028.[13]
However, despite the UK’s promise, evidence suggests an increasing proportion of global R&D investment is being placed elsewhere. Although the UK retains a long-standing global reputation for high-quality research in both academic institutions and biopharmaceutical companies,[14]
- The National Institute for Health Research (NIHR) has warned that as expertise and capabilities emerge around the world – and in particular, in China and Brazil – biopharmaceutical companies are increasingly looking beyond traditional markets when making R&D investment decisions.[14]
- In each of the last three years the UK’s share of patients recruited to global clinical studies has fallen year-on-year and is now just 3%[15] – and just 2% in the early-stage Phase II trials, in which the UK should excel.[16]
The NIHR has noted that the UK’s declining share is due to a number of factors, including the size of the potential patient pool and the burden of setting up research studies [14] – which are both factors that can be addressed by unlocking the promise of UK health data.
Improving the UK’s health data environment has therefore been a priority of the UK Government and the industry for many years. In 2013, for example, the ABPI developed its Big data road map,[17] and in 2017 our members helped support the Life Sciences Industrial Strategy, which pressed for the development of platforms to enable health data to be appropriately shared for the research and development of new technologies.[18]
In 2021 government published it’s Life Sciences Vision, which identified harnessing the potential of UK health data as a "precondition for success”.[77]
The following pages explore our perspectives on this process, and what more needs to be done.
Last modified: 23 May 2024
Last reviewed: 23 May 2024